
Learning the World - Why VL-JEPA 2 Matters
From Observation to Latent Dynamics

An examination of how world models can be learned from observation, and why representation quality—not scale alone—determines planning capability.
Part 4 of 5 in the “Beyond Tokens” series.
Learning Dynamics, Not Just Patterns
Essays 1 through 3 established two conclusions. Token-based systems fail when reasoning must persist over time, and world models are the architectural response that makes planning possible. What remains unresolved is the most practical question of all: how are such world models acquired in real systems?
Manually specifying environment dynamics does not scale. Real-world environments are noisy, partially observable, and continuously changing. Any attempt to hard-code rules or transitions quickly collapses under complexity. If world models are to serve as a foundation for reliable systems, they must be learned from experience, not engineered in advance.
This is where objectives such as VL-JEPA 2 become important—not as a new class of multimodal model, but as a method for learning predictive structure directly from observation. VL-JEPA 2 formalises this shift by training models to predict how latent representations of the world evolve, rather than optimising for reconstruction or token-level accuracy. Rather than relying on dense supervision or task-specific rewards, these approaches train systems to form internal representations that evolve predictably as the world changes. The result is not better pattern matching, but a more durable internal model of how states change over time.
For leadership teams, this reframes the central question. The challenge is no longer how large a model can be made, but what kind of structure the system is actually learning—and whether that structure supports planning, generalisation, and adaptation as conditions change.
From Pattern Matching to Latent Dynamics
Learning a world model is fundamentally different from learning correlations in data.
A token-based model learns to continue sequences. A world model learns to predict how latent state evolves over time, even when that state is only partially observable. This distinction is often described using the language of Partially Observable Markov Decision Processes (POMDPs), but the intuition is simpler than the terminology suggests.
In most real systems, you never see the full state of the world. You see observations—logs, metrics, images, prices, sensor readings—that provide incomplete and noisy signals. A world model must infer an internal belief about what is happening and update that belief as new observations arrive and actions are taken.
The challenge, then, is not just predicting the next observation, but learning a latent representation that captures what matters for future decisions. This is the core shift from pattern matching to dynamics modeling.
What VL-JEPA 2 Actually Contributes
VL-JEPA 2 is best understood not as a replacement for existing models, but as a learning objective designed to solve a specific problem: how to learn stable, predictive latent representations without explicit labels.
Rather than training a model to reconstruct future observations directly, JEPA-style objectives train the model to ensure that different views of the same underlying process remain consistent over time. In practice, this means learning representations where future states are predictable in latent space, even if raw observations vary widely.
This matters because it aligns naturally with world modeling. A good world model does not need to predict every detail of the future; it needs to predict what will be true about the world after an action is taken.
From a systems perspective, VL-JEPA 2 reduces dependence on hand-labeled trajectories, encourages abstraction over irrelevant detail, and produces representations that remain coherent under long-horizon prediction.
Crucially, it addresses how world models can be learned, not whether they should exist.
Multimodality Is Incidental, Not Central
Much of the attention around VL-JEPA 2 focuses on multimodality—vision, language, and action combined at scale. While important, this can obscure the more general point.
Multimodal inputs are simply multiple observation channels into the same underlying state. Vision matters in robotics because it is the richest available signal. In enterprise systems, other channels dominate: event streams, financial data, configuration graphs, or logs.
The learning problem is the same in all cases. The model must discover which aspects of its observations are predictive of future state transitions and which can be safely ignored.
Seen this way, VL-JEPA 2 is not about images or language per se. It is about learning dynamics from partial, heterogeneous evidence—a requirement shared by almost every real-world system.
Why Learning Alone Is Not Enough
It is tempting to treat learned world models as the solution to everything that came before. That temptation is understandable—and wrong.
A system can learn highly plausible dynamics and still fail in practice if those dynamics are never tested against consequence. Learning improves the quality of internal representations, but it does not, by itself, guarantee that those representations are correct, consistent, or safe to act upon. A learned model can be coherent and still be wrong in ways that only surface once decisions accumulate.
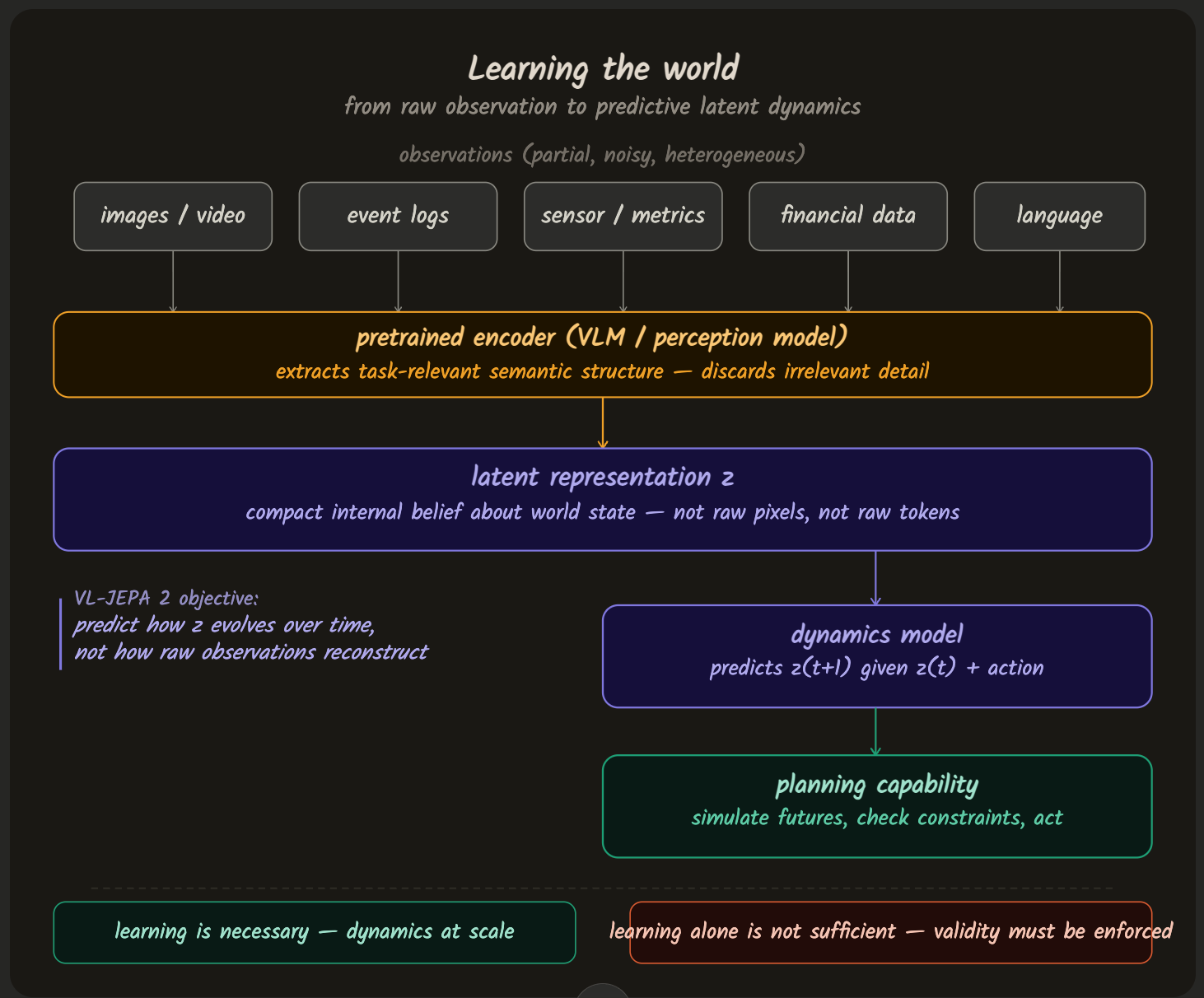
This is where the threads of the series converge. Planning requires state. State requires dynamics. Dynamics must be learned. But learning alone does not enforce validity. Without a mechanism to check transitions, constrain actions, and detect violations, learned world models simply replace hand-coded assumptions with learned ones.
The result is a system that may generalise better, but remains fundamentally unaccountable. It can imagine futures, but nothing forces those imagined futures to correspond to what would actually happen.
This is why VL-JEPA 2 belongs after world models and planning are understood, not before. It is a powerful mechanism for learning dynamics at scale—but it does not define how those dynamics are executed, verified, or enforced. Learning is necessary, but it is not sufficient.
That distinction sets the stage for the final part of the series. If world models are to support real planning under real constraints, they must move beyond representation and into execution.
From Learned Models to Reliable Systems
At this point in the series, the role of VL-JEPA 2 should be clear—and deliberately bounded.
It explains how world models can be learned from experience rather than specified in advance. By training systems to predict how latent representations evolve, VL-JEPA 2 supports abstraction across environments and provides the raw internal structure that planning requires. It answers the question of how dynamics enter the system at scale.
What it does not answer is a different—and more demanding—question: when should a system be allowed to act?
Learning produces representations. Planning uses them. But reliability only emerges when those representations are embedded in systems that can simulate outcomes, check transitions, and constrain behaviour before action is taken. Without that loop, even well-learned dynamics remain descriptive rather than operational.
This is the final transition the series must make. The move from learning how the world works to building systems that are accountable to that understanding.
The final essay completes that arc. It shows how world models, planning, and learning are assembled into executable systems—systems that can be tested, verified, and trusted to operate under real constraints.