
From World Models to Working Systems
Making Intelligence Executable

A practical synthesis showing how world-model ideas become executable, verifiable systems that can be built, tested, and trusted.
Part 5 of 5 in the “Beyond Tokens” series.
What This Essay Is — and Why It Exists
The first four essays in this series followed a deliberate progression.
We began by examining why token-based systems fail under real operational constraints: not because they cannot reason, but because their reasoning remains detached from consequence. We then introduced world models as the correct abstraction for systems that must persist, accumulate state, and act repeatedly in the same environment. From there, we showed how planning—often treated as a capability upgrade—actually exposes architectural weaknesses when systems are allowed to imagine futures they cannot safely commit to. Finally, we explored how world models can be learned from observation, rather than hand-engineered, without abandoning structure.
Together, those essays explained what breaks in modern AI systems—and why.
This final essay plays a different role.
It is written for builders: CTOs, engineers, architects, and technically fluent product leaders who now face a more operational question:
How do these ideas become systems that can actually be built, tested, and trusted?
Not in theory, but in code.
Not as demos, but as architectures that continue to behave correctly when plans fail, constraints bind, and decisions accumulate over time.
This essay does not introduce a new theory of intelligence. Instead, it consolidates the ideas developed so far into a minimal, executable form. It marks the transition from analysing failure modes to defining a concrete path forward: what to implement, what to verify, and what to enforce if planning is to be safe to rely on.
To make that transition tangible, the essay is paired with an end-to-end reference implementation, published openly on GitHub:
The example uses a deliberately simple trading scenario. The code is intentionally modest. Its purpose is not performance or sophistication, but architectural clarity—to show how world models, planning, and verification come together in a system that can be reasoned about before it acts.
From Reasoning to Enforcement
Across the series, we have steadily tightened the loop between reasoning and reality.
Token-based systems reason effectively, but only within a narrow local context.
World models introduce persistent state, but often remain architecturally isolated.
Planning systems can enumerate futures, but may still commit actions without enforcement.
What separates impressive systems from reliable ones is enforcement.
In practice, enforcement is often misunderstood. It is confused with guardrails, prompt constraints, or output filters—mechanisms that operate after reasoning has already occurred. These tools can shape what a system says, but they do not govern what it does.
World-model-based enforcement operates at a deeper level. Constraints are applied to state transitions, not text. Actions are evaluated based on whether their simulated consequences are valid within an explicit model of the world.
In the reference implementation, this distinction is made concrete. Every proposed action—whether produced directly or via a planner—is passed through the same loop:
Plan → Simulate → Verify → Execute
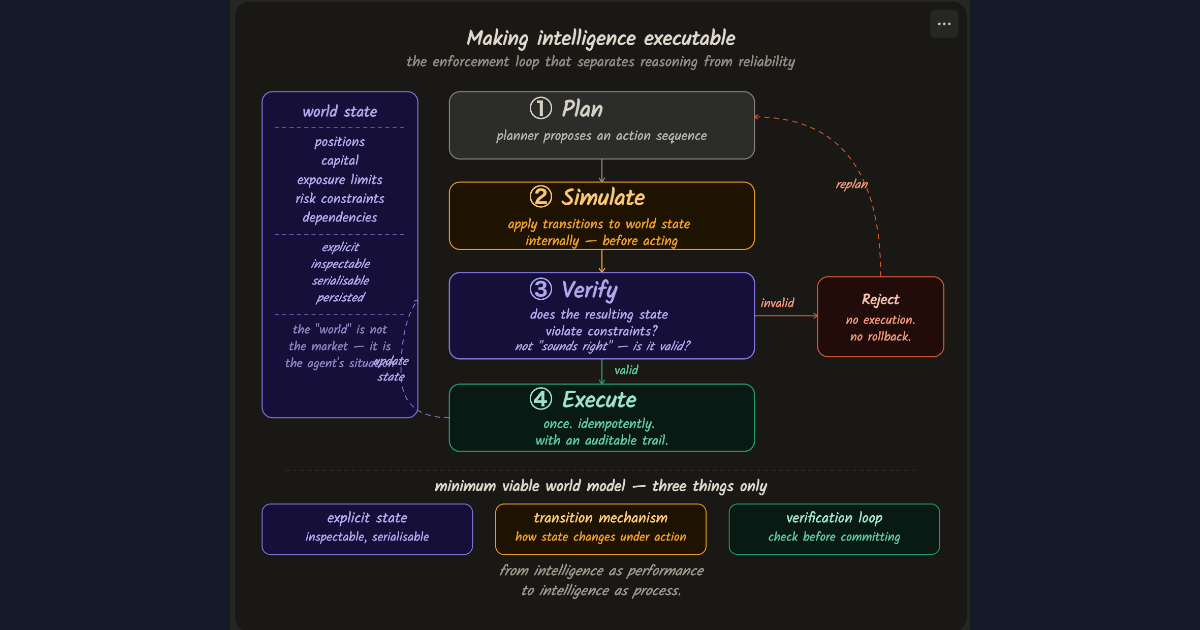
Figure 1. From Plan to Execution: An Enforced Decision Loop
If a simulated transition violates constraints—insufficient capital, leverage limits, concentration thresholds—the action is rejected. No execution occurs. No rollback is required.
An invalid action is never executed, not because it “sounds wrong,” but because it produces a state that violates explicit invariants.
This shift—from filtering outputs to enforcing dynamics—is what allows systems to behave predictably under pressure.
The Minimum Viable World Model
World models can sound abstract, so it is useful to define the smallest version that meaningfully changes system behaviour.
A Minimum Viable World Model consists of three elements:
An explicit, inspectable representation of state.
A defined mechanism by which state changes under action.
A verification loop that checks predicted transitions before execution.
Nothing more is required to cross the threshold from reactive agents to enforceable systems.
In the trading example implemented in the repository, the “world” is not the market. It is the agent’s situation: current positions, available capital, exposure limits, and risk constraints. This state is explicit, serialisable, and persisted.
An action—placing an order or adjusting exposure—implies a state transition. Capital changes. Risk metrics shift. Constraints tighten or loosen.
Before execution, the system simulates that transition. If the resulting state violates constraints, the action is rejected. The rejection is recorded, explained, and surfaced as a decision artifact that can be inspected after the fact.
No forecasting is required.
No reinforcement learning is required.
What matters is that consequences are checked before commitment. That alone eliminates a large class of failures common in token-based agents.
What You Should See (If the System Is Doing the Right Thing)
The purpose of the reference implementation is not to impress, but to make failure modes legible.
When you run the system—locally or on AWS—you should see two things happen repeatedly.
First, plans that look superficially reasonable are rejected. A planner proposes a sequence of actions. The system simulates them step by step. A constraint binds—capital runs out, exposure spikes, concentration limits are exceeded. The plan is rejected before execution, and the reason is explicit.
Second, plans that pass simulation are executed once, idempotently, and leave behind an auditable trail. State changes are persisted. Deltas are recorded. The decision to execute is explainable in terms of state transitions, not model confidence.
This is not a toy outcome. It is the behaviour that separates systems that reason from systems that can be trusted.
Essays to Systems: How the Series Maps to the Code
The repository is not an afterthought. It is the execution of the ideas in this series, versioned deliberately to mirror their development.
The ideas in Essays 1 and 2—why tokens fail and why world models matter—are embodied in the explicit state representation and constraint enforcement introduced in v1.1. This is the point at which reasoning becomes grounded in persistent state.
Essay 3, which treated planning as a stress test rather than a capability upgrade, maps directly to v2.0. Here, planning is introduced as an upstream proposal mechanism, but execution remains strictly gated by simulation and verification.
Essay 4’s focus on learned world models informs v2.1, where planners become provider-neutral and learned dynamics can be integrated without changing the enforcement loop.
Finally, v2.2 extends the same architecture into AWS, demonstrating that the pattern survives deployment: the same Plan → Simulate → Verify → Execute loop, the same rejection semantics, the same auditability.
Each version is a milestone, not a rewrite. The architecture compounds rather than pivots.
Where Learning Fits — and Why Timing Matters
Learning is not absent from this system. It is simply not allowed to run ahead of structure.
Approaches like VL-JEPA 2 matter precisely because they allow predictive representations to be learned from observation, rather than labelled reward. They help models internalise dynamics that would otherwise need to be hand-engineered.
But learning only adds value once an executable loop exists.
Applied too early, it accelerates behaviour without accountability. Applied after a Minimum Viable World Model is in place, it allows dynamics to be learned rather than specified—without sacrificing control.
Learning scales structure. It does not replace it.
What “Getting Started” Actually Means
For builders, getting started does not mean training a new foundation model.
It means answering three questions explicitly:
What is the state of my system?
How does that state change under action?
Where do I verify those changes before committing?
If those questions have concrete answers—even simple ones—you are already building with world models.
Everything else is optimisation.
Closing the Loop
The earlier essays explained why world models matter, why planning exposes architectural limits, and how world models can be learned from observation.
This essay completes the arc by showing how those ideas become executable systems—systems that can be simulated, verified, and trusted before they act.
Not by making models more articulate.
But by making their understanding confront reality.
That is the transition this series has been building toward:
from intelligence as performance
to intelligence as process.
What Comes Next
The work now moves fully from prose into code.
The repository will continue to evolve—introducing richer simulations, learned dynamics, and more sophisticated planning strategies—but the core architecture is already in place.
At this point, the question is no longer whether world models matter.
It is how deliberately we choose to build with them.
This piece truely made me think. The shift from abstract world models to verifiable systems resonates, much like building reliable core strength in Pilates, not just isolated exercises. It's all about consistent, trustable actions.